| Mainframes can achieve "four nines" or "five nines"
availability: 99.99 or 99.999 percent uptime. That
translates into only 5 to 53 minutes of downtime per year.
In fact, IBM's Server Group claims that the mean time
between critical failures (MTBCF) for its System/390
mainframes — that is, the average time between failures
that force a reboot and an initial program load — is 20
to 30 years. Millions of PC users would be overjoyed with an MTBCF of just one day. Yet mainframes are big, complex systems that often have clusters of CPUs, gigabytes of main memory, and thousands of users. What makes them so reliable? Mainframe experts say that it's a matter of priorities. When a PC crashes, even the system administrator might not hear about it, much less the vendors who made the system, the OS, and the application software. The user shrugs, reboots, and keeps right on working. When a mainframe crashes, however, it's a major catastrophe. It's General Motors calling up IBM to demand answers. And even if GM doesn't make the call, the mainframe does. Periodically, the massive machines dial up IBM's lab in Poughkeepsie, New York, to upload error logs and download updates. "Even if it doesn't crash, we know about it," says Lisa Spainhower, System/390 senior technical staff member. During the beginning of the 1980s, Big Blue set a goal of increasing availability by a factor of 100, as measured by yearly uptime. IBM achieved that goal, says Spainhower. "Frankly, we didn't do it because it was a fun engineering project," she explains. "We did it because our customers demanded it." Because everyone keeps detailed logs, problems rarely get ignored for long. There's too much at stake. Of course, it helps that mainframes have full-time technicians available to keep them up and running. They also have redundant hardware, extremely protective OSes, and stable applications. "The design of a crash-proof system must be pervasive," explains Guru Rao, System/390 chief engineer. "It starts with your choice of technology and components, and it extends all the way to the design of the OS, the hardware and software, and the customer's applications." System/390 maintains separate memory partitions for the OS (OS/390), the software-subsystem components (e.g., DB2 database drivers), the transactional middleware (e.g., the Customer Information Control System, or CICS), and the applications. IBM introduced this so-called Enterprise Systems Architecture (ESA) in the late 1980s, basing it on the earlier partitioning of MVS (Multiple Virtual Storage). Compared to MVS, ESA has more partitions and faster interprocess communications (IPC). As a result, it's exceedingly rare for a crashed application to bring down the entire system. Even if a critical middleware component, such as CICS, fails, System/390's automatic restart manager can restore the task. "These systems, like PCs, do fail," notes Spainhower. "It's just that when they fail, they detect the errors and recover from them with greater reliability." Interestingly, mainframe OSes aren't any bigger than OSes for PCs. They contain a lot less code to support GUIs, and a lot more code for error detection, error isolation, and recovery. They're not growing as fast as OSes for PCs are, and their code tends to remain more stable. "It would almost take an act of God to change the dispatcher in IBM's mainframe OS," says Dr. Barry Feigenbaum, senior software engineer for IBM network-computing software solutions. "It's not quite the same on PC OSes." As ambitious PC vendors try to encroach on the territory of enterprise servers, they will have to address the same concerns that mainframe vendors did in the 1980s. The contest isn't about megahertz and megabytes; it's about high availability. And that will require PC vendors to radically change their priorities. IBM OS/390 System Architecture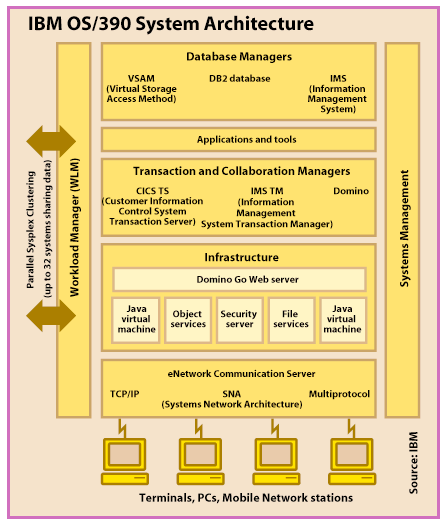 Copyright 1994-1998 BYTE |