| For Intel and Hewlett-Packard, the year 2000 isn't a
problem — it's an opportunity. In late 1999, Intel plans
to ship Merced, the first microprocessor based on a
next-generation architecture jointly conceived by the two
companies. Although this 64-bit architecture builds on
years of research at Intel, HP, other companies, and
universities, it is radically different from anything ever
attempted on a mass-market scale. Whether it succeeds or
fails, one thing is certain: It will change the computer
industry forever. Known as Intel Architecture-64 (IA-64), the new definition breaks clean with the past in a startling fashion. IA-64 is emphatically not a 64-bit extension of Intel's 32-bit x86 architecture. Nor is it an adaptation of HP's 64-bit PA-RISC architecture. IA-64 is something completely different — a forward-looking architecture that uses long instruction words (LIW), instruction predication, branch elimination, speculative loading, and other advanced techniques to extract more parallelism from program code. Although Intel and HP promise backward compatibility with today's x86 and PA-RISC software, they're still withholding those details. Compatibility will not be trivial because IA-64 goes far beyond the 32-bit extensions that Intel added to the x86 in 1985, as well as the 64-bit extensions that HP added to PA-RISC in 1996. It's worth remembering that the x86's much less radical transition from 16 to 32 bits has so far taken 12 years and still is not complete. The migration to IA-64 won't concern most users in the short term, however, because Intel says it's designing Merced for high-end servers and workstations. Merced is not for mainstream PCs. In fact, Intel says IA-64 won't replace the x86 "for the foreseeable future." It's likely that Intel (and other x86 vendors) will continue to introduce new generations of x86 chips for years to come. Superwide CPUs Before plunging neck-deep into the technical innards of IA-64, it is critical to understand why Intel and HP are gambling their futures on such sweeping changes. It comes down to this: Intel and HP think CISC and RISC are running out of gas. Intel's x86 is an ancient CISC architecture that dates back to 1978. In those days, CPUs were scalar devices (able to execute only one instruction at a time) with little or no pipelining. Chips had tens of thousands of transistors. HP's PA-RISC architecture dates back to 1986, when superscalar (multiple-instruction) pipelines were just starting to sprout and chips had hundreds of thousands of transistors. In the late 1990s, leading-edge processors have millions of transistors. By the time Merced makes its debut, Intel will be rolling out the next generation of process technology beyond today's latest 0.25-micron process — 0.18-micron. Even the first IA-64 chips will have tens of millions of transistors. Future generations will have hundreds of millions. CPU architects are eager to put those transistors to work. They want to design chips with many more functional units — that execute more instructions in parallel — but they're hitting a wall of complexity. As they add more units to make the CPU "wider," they must also add more control circuitry to dispatch those instructions to the units. Today's best CPUs can't retire more than four instructions per clock and already waste too much silicon on this purely bookkeeping logic. At the same time, the sequential nature of program code and the frequency of branches make it increasingly difficult to dispatch instructions in parallel. Today's CPUs devote enormous amounts of logic to minimizing branch penalties and to extracting as much hidden parallelism as possible from the code. CPUs reorder instructions on the fly, predict where branches will jump, and speculatively execute instructions beyond the branches. If the CPU guesses wrong, it must discard the speculative results, flush the pipelines, and reload the correct instructions — paying a heavy penalty in lost cycles. CPUs that theoretically can retire four instructions per clock actually average less than two per clock. To compound these problems, memory chips haven't come close to matching the soaring clock speeds of CPUs. When Intel designed the first x86 chip, CPUs could fetch data from memory as fast as they could process the data. Today, CPUs spend hundreds of clock cycles waiting for data to arrive from memory, despite having large, fast caches. Intel and HP are addressing all these problems. Here's what they divulged in two lengthy interviews with BYTE: • The new IA-64 format packs three instructions into a single 128-bit-long bundle for faster processing. Usually this is called LIW encoding, but Intel shuns that label, saying LIW has "negative connotations." For the same reason, Intel does not like to describe the individual instructions as "RISC-like," even though they are fixed-length and presumably optimized for single-cycle execution in a core that doesn't need microcode. Intel calls its new LIW technology Explicitly Parallel Instruction Computing, or EPIC. At any rate, IA-64 is nothing like the x86. An x86 instruction is a single unit that can vary from 8 to 108 bits long, and the CPU must tediously decode each instruction while scanning for the instruction boundaries. (See the figure "IA-64 Instruction Format".) • Each 128-bit IA-64 bundle contains a template of several bits — placed there by the compiler — that explicitly tells the CPU which instructions it can execute in parallel. No longer must the CPU hurriedly analyze the instruction stream at run time to uncover hidden parallelism. Instead, the compiler identifies the parallelism and binds this information into the machine code. Each instruction contains three 7-bit general-purpose register (GPR) fields, and the fields are specific to integer and floating-point (FP) instructions. That means IA-64 processors will have 128 integer-type GPRs and 128 FP registers. All are programmer-visible, random-access registers. Compare that to the constipated x86, which has eight integer GPRs and an eight-entry FP stack. IA-64 processors can be much wider and will stall less often due to false dependencies (e.g., shortages of registers). • IA-64 compilers will use a technique called predication to remove the penalties caused by mispredicted branches and the need to jump over blocks of code beyond branches. When the CPU encounters a predicated branch at run time, it will begin executing the code along all destinations of the branch, exploiting as much parallelism as possible. When the CPU discovers the actual branch outcome, it stores the valid results and discards the others. • IA-64 compilers will scan the source code to find upcoming loads from memory, then will add a speculative load instruction and a speculative check instruction. At run time, the first instruction loads the data from memory before the program needs it. The second instruction verifies the load before letting the program use the data. Speculative loading helps hide the long latencies of memory accesses and helps increase parallelism. One implication of IA-64 is that compilers will have to be a lot smarter about the microarchitectures of the CPUs they target. Existing chips — even RISC chips with optimized compilers — do much more optimizing at run time than IA-64 chips will. IA-64 transfers the job of optimizing the instruction stream to the compiler. Successive generations of IA-64 processors will run older IA-64 software, but the software might not run at top speed until it's recompiled. In the IA-64 age, developers might have to ship multiple binaries to get the best performance on a broad installed base of IA-64 systems. Another impact will be code expansion. IA-64 instructions are longer than 32-bit RISC instructions — about 40 bits each. Just by recompiling existing code, developers will almost certainly see their programs grow larger. And those programs will probably take longer to compile because IA-64 demands a lot more work from the compiler, as we'll see in a moment. Intel and HP say they're already working with tool vendors to help them revise their products. Disappearing Branches Predication is a prime example of the new burden shifted onto compilers. This technique is central to IA-64's branch elimination and parallel instruction scheduling. Normally, a compiler turns a source-code branch statement (such as IF-THEN-ELSE) into alternate blocks of machine code arranged in a sequential stream. Depending on the outcome of the branch, the CPU will execute one of those basic blocks by jumping over the others. Modern CPUs try to predict the outcome and speculatively execute the target block, paying a heavy penalty in lost cycles if they mispredict. The basic blocks are small, often two or three instructions, and branches occur about every six instructions. The sequential, choppy nature of this code makes parallel execution difficult. When an IA-64 compiler finds a branch statement in the source code, it analyzes the branch to see if it's a candidate for predication. Compilers can't predicate every branch: Dynamic method calls that the CPU won't discover until run time are one obvious exception. In other cases, predication might cost more cycles than it saves. Compilers will have to be clever about this. If the compiler determines that predication makes sense, it marks all the instructions that represent each path of the branch with a unique identifier called a predicate. For example, the compiler might tag each instruction that follows the TRUE condition with the predicate P1; and it might tag each instruction that follows the FALSE condition with the predicate P2. IA-64 defines a 6-bit field in each instruction to store this predicate. Thus, there are 64 unique predicates available at one time. Any number of instructions that share a particular branch path will share the same predicate. After tagging the instructions with predicates, the compiler determines which instructions the CPU can execute in parallel. Again, this requires the compiler to know a lot about the CPU's microarchitecture, because different IA-64 chips will have different numbers and types of functional units. Also, of course, the compiler must watch out for data dependencies — an operation that needs the result of a previous operation cannot execute in parallel with that operation. But the compiler will almost always find some parallelism by pairing instructions from different branch outcomes because they represent independent paths through the program. Now the compiler can start assembling the machine-code instructions into 128-bit bundles of three instructions each. The bundle's template field not only identifies which instructions in the bundle can execute independently but also which instructions in the following bundles are independent. So if the compiler finds 16 instructions that have no mutual dependencies, it could package them into six different bundles (three in each of the first five bundles, and one in the sixth) and flag them in the templates. The bundled instructions don't have to be in their original program order, and they can represent entirely different paths of a branch. Also, the compiler can mix dependent and independent instructions together in a bundle, because the template keeps track of which is which. Unlike some previous very-long instruction word (VLIW) architectures, IA-64 does not insert null-operation instructions (NOPS) to fill slots in the bundles. At run time, the CPU scans the templates, picks out the instructions that do not have mutual dependencies, and then dispatches them in parallel to the functional units. The CPU then schedules instructions that are dependent according to their requirements. When the CPU finds a predicated branch, it doesn't try to predict which way the branch will fork, and it doesn't jump over blocks of code to speculatively execute a predicted path. Instead, the CPU begins executing the code for every possible branch outcome. In effect, there is no branch at the machine level. There is just one unbroken stream of code that the compiler has rearranged in the most parallel order. At some point, of course, the CPU will eventually evaluate the compare operation that corresponds to the IF-THEN statement. Now the CPU knows the outcome. Let's say the condition is TRUE, so the valid path is predicate P1, not P2. The 6-bit predicate field in each IA-64 instruction refers to a set of 64 predicate registers (P0-P63), and each register is 1 bit wide. The CPU will store a 1 in predicate register P1 to represent TRUE, and it will store a 0 in predicate register P2 to represent FALSE. By this time, the CPU has probably executed some instructions from both possible paths. But it hasn't stored the results yet. Before taking that final step, the CPU checks each instruction's predicate register. If the register contains a 1, the instruction is valid, so the CPU retires the instruction and stores the result. If the register contains a 0, the instruction is invalid, so the CPU discards the result. (See the figure "How Predication Works".) Predication effectively removes the negative impact of a branch at the machine level while preserving branch behavior. Again, it can't remove every branch. However, if the compiler cannot predicate a branch, or chooses not to, an IA-64 processor will behave much like a conventional processor: It will try to predict which way the branch will turn, and it may speculatively execute some instructions along the predicted path. Simulations of this strategy indicate that predication can eliminate more than half of the branches in a typical program — and therefore reduce by half the number of potential mispredictions. This has several benefits. It reduces code fragmentation at the machine level because the compiler can merge small basic blocks into larger blocks that branches don't chop up. Larger blocks give the compiler more freedom to rearrange instructions for parallel execution. It also drastically reduces the hazard of mispredicted branches because every branch doesn't require the CPU to play fortune-teller. And it keeps the functional units busy because the CPU can dispatch more instructions in parallel. The downside of predication is that the CPU always executes instructions it's going to throw away. Whether the predicated condition evaluates TRUE or FALSE, the CPU does perform redundant work. The trick, of course, is to make sure the CPU saves more clock cycles than it wastes. Clearly, predication assumes that IA-64 compilers will be smart and that IA-64 processors will be very wide superscalar chips with lots of resources to spare. When you're rich, you can afford to spend lavishly. He Ain't Heavy, He's My Data Another key feature of IA-64 is speculative loading. Not only will this allow IA-64 processors to load data from memory before the program needs it, it will also postpone the reporting of exceptions if the load is not legal. In geekspeak, this technique allows the CPU to hoist the load operation higher in the instruction stream — in some cases, even above a branch. The goal is to separate the loading of data from the use of that data. By paying attention to this, the CPU won't have to twiddle its thumbs while waiting for data in slow memory to show up. Like predication, it's a combination of compile-time and run-time optimizations. First, the compiler analyzes the program, looking for any operations that will need data from memory. Whenever possible, the compiler inserts a speculative load instruction at an earlier point in the instruction stream, well ahead of the operation that will actually use the data. The compiler also inserts a matching speculative check instruction immediately before the particular operation that will use the data. At the same time, of course, the compiler rearranges the surrounding instructions so that the CPU can dispatch them in parallel. At run time, the CPU encounters the speculative load instruction first and tries to retrieve the data from memory. Here's where an IA-64 processor differs from a regular processor. Sometimes the load will be invalid — it might belong to a block of code beyond a branch that has not executed yet. A traditional CPU would immediately trigger an exception. If the program could not handle the exception, it would likely crash. But an IA-64 processor won't immediately report an exception if the load is invalid. Instead, the CPU postpones the exception until it encounters the speculative check instruction that matches the speculative load. Only then does the CPU report the exception. By then, however, the CPU has resolved the branch that led to the exception in the first place. If the path to which the load belongs turns out to be invalid, then the load is also invalid, so the CPU goes ahead and reports the exception. But if the load is valid, it's as if the exception never happened. (See the figure "How Speculative Loading Works".) Speculative loading is similar to the TRY-CATCH structures in some programming languages, except that it works at the machine level. In Java, for instance, a TRY statement will attempt a risky operation, such as opening a file. If TRY succeeds, the program continues normally. If the system can't open the file and throws an exception, CATCH grabs it and stops the program from crashing. IA-64's speculative check is a safety valve for exceptions, like CATCH. This technique, combined with predication, gives the compiler much more flexibility to reorder instructions and increase parallelism. The ability to hoist loads above branches is particularly powerful. Since branches typically occur about every six instructions, they would severely inhibit IA-64's ability to load data from memory long before it's needed. It would be almost impossible to retrofit an existing architecture with these features because the compiler and the CPU must collaborate to make it happen. Beyond RISC In the heady days of the 1980s, some RISC engineers ridiculed CISC and foretold the doom of the x86 family. Unfortunately for them, the penalty for underestimating Intel is even greater than the penalty for mispredicting branches. Business and technology are two different things. RISC might be technically superior to CISC, but Intel's vast resources and the momentum of DOS and Windows have kept the x86 competitive. Now, Intel says RISC is running out of gas. Could it be that Intel might be making the same mistake that RISC fans made in the 1980s? Will RISC stave off the IA-64 challenge? It's too early to tell. However, it's doubtful that RISC vendors can tap the same depth of resources that keeps the x86 alive. The most popular RISC architecture (not counting embedded applications) is the PowerPC. And the only high-volume PowerPC vendor is Apple, a company struggling for survival. Without more business, how long can RISC vendors justify the expensive research and development it takes to battle Intel? IA-64 chips are still two years away. Intel's competitors — from both the RISC and the CISC camps — have that much time to take the offensive. IA-64: What's Different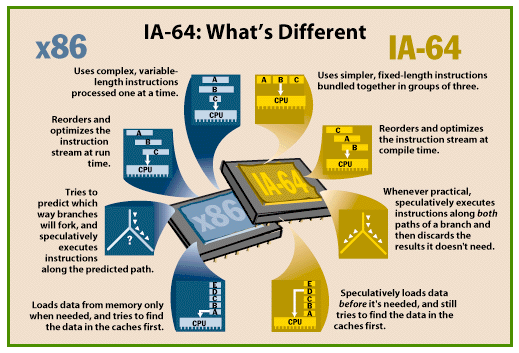 IA-64 Instruction Format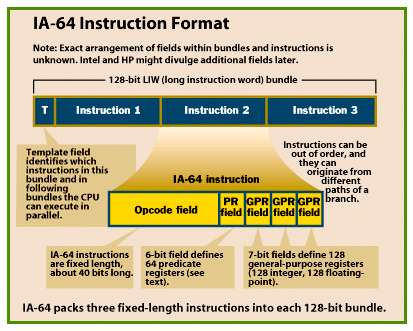 How Predication Works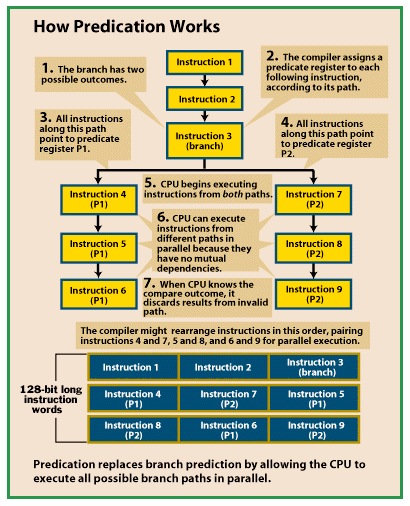 How Speculative Loading Works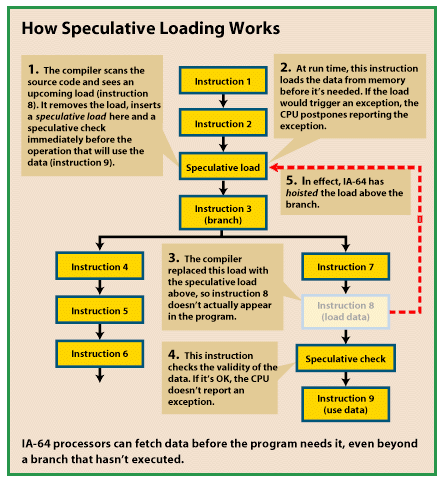 Tom R. Halfhill is a BYTE senior editor based in San Mateo, California. You can reach him at thalfhill@byte.com. Inbox / March 1998Beyond the 32-Bit Operating SystemI read "Beyond Pentium II" (December Cover Story) with great interest. I wonder what corresponding "radical" changes the IA-64 architecture means for operating systems, especially Microsoft Windows? Given the time frame and sponsorship, the introduction of IA-64 will have to coincide with a new OS, perhaps even one fundamentally rethought! Undoubtedly, the view from Redmond might be an important follow-up article. Lynn Hopffgarten hopffgarten@knight-hub.com IA-64 will require a new 64-bit OS. The current 16- and 32-bit versions of Windows will still run on IA-64, of course, but only in x86 backward-compatible mode. The performance will be less than what you'd get from the best x86 processors available at the time Merced ships. To get the most from IA-64, you'll need a new 64-bit OS and new 64-bit applications. Microsoft is already working on a 64-bit version of Windows NT. I think it's unlikely that Microsoft will port any other OS to IA-64; the current line of Windows 95/98 will always run on x86. On the Unix front, SCO is working on UnixWare 64 with assistance from Hewlett-Packard, HP is working on its own 64-bit HP-UX, Digital is adapting its version of Unix, and Sun is porting Solaris to IA-64. We'll have more articles on this subject as information becomes available. — Tom Halfhill, senior editor EPIC Flaw I'm not so convinced of Intel's Explicitly Parallel Instruction Computing (EPIC) idea. Long instruction word (LIW) didn't get a bad name out of malice; the idea didn't work. It was an extension of the early RISC notion of making the compiler schedule to the pipeline, a bad idea because much parallelism is possible to discover only at run time, and recompiling every time a new microarchitecture is designed is a nonstarter. (Think of the time it took before we saw applications with Pentium-specific code.) I'm betting on PowerPC to deliver performance in the short term. The PowerPC750 is theoretically less superscalar than the 604e/Pentium II generation, yet it's faster. Why? More attention paid to making sure it does get close to its peak throughput rate through better memory architecture, better speculative execution, etc. Translate these gains to a design that can dispatch four or more instructions per clock at 500MHz plus, which is what I expect of the PowerPCG4, and you're talking real speed. Check out IBM's Power3 design for a hint of what's to come. Philip Machanick Dept. of Computer Science University of the Witwatersrand South Africa The PowerPC750 is impressive. The latest Power Macs bear this out with their performance — higher than any single-processor x86-based PCs, according to some benchmarks. In the long term, however, I still have doubts that RISC vendors will be able to keep up with Intel. Without high-volume sales, it's hard to justify the expensive R&D it takes to compete. It will be interesting to see how often IBM and Motorola introduce new PowerPC cores in the years to come. I suspect they have enough new designs in the pipeline to last for a couple of years; beyond that, it gets fuzzy. I hope, for the sake of competition, the PowerPC doesn't die. Look for our story on the Power3 in the Core section of the April issue. — Tom Halfhill Lose an Opcode? What I don't get about IA-64 is why all instructions that rely on the speculative check can't make an implicit speculative check themselves and report an exception just as a pure speculative check may need to do. This would do away with that opcode. I find the check instruction most inefficient. Ernesto A. Pérez Isabela, Puerto Rico The speculative check instruction must be separate from the speculative load because the CPU can't always determine the validity of the data when speculatively loading it from memory. The load may or may not cause an exception. Often, the CPU won't resolve that outcome until several instructions later, after a branch. Furthermore, it wouldn't save time to combine the speculative load and the speculative check in a single instruction. Checking for the exception would lengthen the execution time of the load instruction. It's better to separate them so the compiler has more flexibility to schedule them in parallel with other instructions. — Tom Halfhill Inbox / April 1998No Wrong GuessI've followed the slow road to Merced with interest. I note, however, the comment in "Beyond Pentium II" (December Cover Story): "Compilers can't predicate every branch: Dynamic method calls...are one obvious exception....Compilers will have to be clever about this." This flaw has always seemed to me the Achilles' heel of very long instruction word (VLIW) processors. As we move to a run-time world of dynamic, independently compiled objects, the notion that compilers can optimize code for an unknown run-time environment seems to mandate, not cleverness, but rather paranormal powers of prediction akin to telepathy. Even calling a DLL function exposes the flaw. How could you know whether the function will return TRUE or FALSE, and therefore optimize your branch prediction, when the code for the DLL was compiled independently? Are we back to static linking again? Still, you do say that "developers will...see their programs grow larger." I loved Lord of the Rings, but I never knew Hewlett-Packard and Intel had secured Gandalf's services. When he's done with Merced, can I book him for my Y2K projects? Andrew Mayo andrew@geac.co.nz We don't know everything about IA-64 yet. Intel and HP are keeping a great deal under wraps. However, we do know that IA-64 isn't betting as much on branch prediction as other CPUs. By executing both paths beyond a branch — both the TRUE and FALSE outcomes — it doesn't need to predict the branch. All it has to do is flip a bit in one predicate register to validate all the instructions along the correct path. There is no such thing as a wrong guess. Of course, this doesn't apply if the compiler can't predicate the branch at compile time. Perhaps IA-64 will fall back on some dynamic optimization to cover those cases. This could even be an implementation question; some IA-64 processors may do some optimizing at run time, and some may not. Or, if the percentage of branches the compiler can't predicate is low enough, maybe it won't be significant. — Tom Halfhill, senior editor Copyright 1994-1998 BYTE |