| Anyone who doesn't rely on a computer or an accountant
to handle their income taxes is all too familiar with the
final ritual of paging through the tax table in the back
of the 1040 book. "If your taxable income is greater than
x but less than y, then your tax is z...." The 1040 tax
table is a classic example of a lookup table: a matrix of
precomputed values that saves you the trouble (and
potential pitfalls) of doing the arithmetic yourself.
Programs often contain lookup tables to avoid executing
lengthy calculations at run time. As long as the values in
the table are correct, the final results will be accurate. It was this quest for speed and accuracy that led Intel to embed a lookup table in the Pentium's FPU, its fifth-generation x86 microprocessor. Stung by the superior floating-point performance of competing RISC processors, Intel wanted to endow the Pentium with an FPU significantly faster than that of any other x86 chip. This would allow Intel to promote the Pentium as a CPU for scientific and engineering applications, as well as the best engine for mainstream software that relies primarily on integer operations. Genesis of an Error Intel's goal was to boost the execution of floating-point scalar code by 3 times and vector code by 5 times, compared to a 486DX chip running at the same clock speed. To achieve that, the Pentium engineers had to improve on the 486's traditional shift-and-subtract division algorithm, which can generate only one quotient bit per cycle. They settled on a new method called the SRT algorithm that can generate two quotient bits per cycle. Named after three scientists who independently conceived it at almost the same time, the SRT algorithm uses a lookup table to calculate the intermediate quotients that are necessary for iterative floating-point divisions. As implemented in the Pentium, the SRT lookup table is a matrix of 2048 cells, although only 1066 of these cells actually contain values. For those that do, the values are integer constants ranging from -2 to +2. The algorithm uses the bit pattern of the divisor as an index into the table. So far, so good. But here is where things went horribly wrong. An engineer prepared the lookup table on a computer and wrote a script in C to download it into a PLA (programmable logic array) for inclusion in the Pentium's FPU. Unfortunately, due to an error in the script, five of the 1066 table entries were not downloaded. To compound this mistake, nobody checked the PLA to verify the table was copied correctly. These five cells are distributed along a boundary of the matrix and should contain the constant +2. Instead, the cells are empty. When the FPU accesses one of these cells, it fetches a zero. This throws off the calculation and results in a number that is always slightly less precise than the correct answer. Because the SRT algorithm is recursive, the shortfall can accumulate during successive iterations of a division operation. At its worst, the error can rise as high as the fourth significant digit of a decimal number (but not the fourth digit to the right of the decimal point, as is commonly believed; the decimal point can be positioned anywhere in the binary floating-point number format). However, the chance of this happening randomly is only about 1 in 360 billion. Usually, the error appears around the 9th or 10th decimal digit. The chance of this happening randomly is about 1 in 9 billion. Because the bit patterns of certain divisors lead to the corruption of quotients derived from certain numerators, the bug occurs only with certain pairs of divisors and numerators — no particular divisor always triggers the bug. The "buggy pairs" can be identified, however, and they always result in a wrong answer on any Pentium chip manufactured before the bug was fixed. Furthermore, the bug potentially afflicts any instruction that references the lookup table or calls FDIV, the basic floating-point division instruction. Related instructions include FDIVP, FDIVR, FDIVRP, FIDIV, FIDIVR, FPREM, and FPREM1. The transcendental instructions FPTAN and FPATAN are also susceptible, though no actual errors have surfaced. The transcendental instructions FYL2X, FYL2XP1, FSIN, FCOS, and FSINCOS were once suspect but are now considered safe. Assessing the Damage The basic facts about the Pentium bug are not in dispute, though they are often misunderstood. For instance, the Pentium does not suffer from a hardware defect in the same sense as a defective appliance or automobile. This is a software bug that's encoded in hardware, and it's the sort of bug any programmer can sympathize with. Users who tolerate a certain level of bugs in their applications and system software should recognize that the same kinds of flaws are inevitable in microprocessors. Unlike memory chips, which are little more than vast arrays of transistors, logic chips can contain complex software mechanisms — such as the FDIV algorithm — that are delivered on silicon instead of on floppy disks. What's different about the Pentium bug is that it doesn't crash your computer — it yields wrong answers so subtle you might never notice anything amiss. But this raises another important issue, which is that binary floating-point math inherently lacks the precision of integer arithmetic. Although computers are still regarded as math machines, they are not really comfortable with floating-point decimal operations. The conversions between binary and decimal, coupled with inherent limits on precision, always result in small errors that are usually ignored. Still, Pentium owners paid for a CPU that's supposed to perform floating-point math to IEEE standards, and that's not what they got. Instead, controversy has raged around additional issues: Intel's dismal customer relations and the wildly conflicting claims of how often the Pentium bug might bite a typical (nonscientific) user. The court of public opinion has ruled on the former subject, but it's not so easy to judge the latter. Intel says a typical spreadsheet user might encounter the bug once in 27,000 years; IBM, which yanked its Pentium systems out of stores in December, says it could happen once every 24 days. Who's right? Unfortunately, this argument will never be resolved to everyone's satisfaction because it hinges on key assumptions about users' behavior. How large are their typical spreadsheets? How often do they recalculate? How many FDIVs are executed? How often do buggy pairs occur? Intel's 27,000-year estimate assumes that the average spreadsheet user will execute 1000 FDIVs per day and that buggy pairs happen randomly. IBM's 24-day estimate assumes 4.2 million FDIVs per day and that buggy pairs happen more often than random chance would suggest. To back up its claims, Intel analyzed 510 spreadsheets from its internal departments (finance, sales/marketing, planning, treasury, product engineering, production control, and tax/customs). A special profiler counted floating-point operations during recalculations and also trapped for divisors containing the telltale bit patterns. Intel says the results confirmed its earlier estimates. IBM insists that buggy pairs crop up more frequently than Intel claims because of a phenomenon dubbed "integer bruising" by Vaughan Pratt, a computer scientist at Stanford University. Pratt builds a formidable argument that common integers — distorted into slightly inaccurate values by seemingly innocuous floating-point operations — can lead to nonrandom frequencies of buggy pairs. (See "How to Bruise an Integer.") To settle this dispute empirically, an independent party would have to replicate Intel's experiment across a statistically valid sample of spreadsheets obtained from a representative selection of companies. Even if such a party could get permission to examine hundreds of proprietary spreadsheets and record users' behavior, the data would take months to gather and analyze. By then, it would be of interest mainly to historians and lawyers. So the ultimate question, "How serious is the bug, really?" will likely go unanswered forever. To paraphrase Albert Einstein, we'll probably never know if God plays dice with the Pentium. Pentium FDIV Error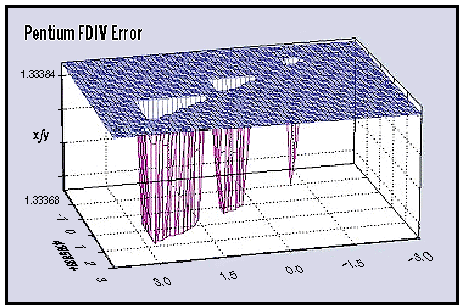 Tom R. Halfhill is a BYTE senior news editor based in San Mateo, California. You can reach him on the Internet or BIX at thalfhill@bix.com. Letters / May 1995The Pentium FPU Bug UnveiledTom Halfhill's "The Truth Behind the Pentium Bug" (March) is the most accurate piece I have seen on the subject. Much has been written about the Pentium processor episode, most of it flat wrong. Good work. Mike Barton Manager of Technical Applications Intel Software Technology Lab Letters / June 1995They're EverywhereIn Tom R. Halfhill's March piece, "The Truth Behind the Pentium Bug," his instructions on how to bruise an integer (page 164) are mind-boggling. I tried the test on several different Pentium machines and they all gave me the binary 10 from the difference of 4.1 and 1.1. When I tried it on our newest Pentium 100, I got the same binary, 10. All our 486 machines gave me 10 as well. I tried a different test I acquired from another magazine and found which systems were using a faulty chip. I wonder if Intel is replacing Pentium chips that are not faulty at all? Cesar Quebral Legend23@ix.netcom.com Integer bruising happens on almost all computers, not just a buggy Pentium. The example I gave was not to reveal whether or not you've got a bad Pentium but to demonstrate how integers can get bruised on any computer. — Tom R. Halfhill Letters / August 1995Comments from TreatAs a mathematician, operations researcher, and computer programmer, I feel I have to respond to Raphael Needleman's March editorial ("Mutant Chips") that warns against depending on heuristic methods, because they may work, but "we don't know why." Neural networks are used for absolutely everything that humans do, and deterministic algorithms cannot duplicate human performance in many cases. This isn't a temporary situation. Chaos theory and Godel's incompleteness theorem both guarantee that we won't be able to solve every problem in a deterministic way. Artificial intelligence — like real intelligence — depends on heuristic methods, and computers won't be doing anything really interesting for us until heuristics are built into chips. I also have to make a comment about the "How To Bruise an Integer" text box in Tom R. Halfhill's article "The Truth Behind the Pentium Bug" (March). A number like 4.1 or 1.1 or 0.1 cannot be exactly represented in binary floating-point values. The binary equivalent of 0.1 (decimal) is 0.0001100110011 (binary), where the "0011" sequence repeats infinitely. That is, the fraction 1/10 has a repeating binary representation, in the same way that 1/3 has a repeating decimal representation. When we use Calculator to do arithmetic, we forget that we are doing things approximately, through binary floating-point notation. That leads to disconcerting results. This is not because we have "bruised an integer," but because we have truncated a floating-point number without realizing it. We are disconcerted because we forget the approximations, not because we use them. It isn't particularly difficult to do such computations accurately. If I wrote Calculator in Smalltalk, with its Fraction class used to represent every number entered in the display, there would be no such errors in ordinary arithmetic. The problem isn't bruised integers; the problem is a poor substitute for arithmetic. Dr. Bobby R. Treat Arlington, VA Bobby.Treat@dp.hq.af.mil Copyright 1994-1998 BYTE |